이번에는 음성 데이터를 분석하는 방법에 대해 다뤄보겠습니다. 아직 공부중이긴 합니다만, 지금까지 진행한 내역들에 대해 초심자의 마음으로 서술하고자 합니다. 혹시 잘못된 내용이 있으면 댓글로 알려주시면 감사하겠습니다.
소리의 형태
우리가 듣는 소리는 진동의 형태라고도 볼 수 있습니다. 공기 중의 진동을 통해 파형이 전달되면서, 그 파형을 귀에서 인지해서 소리를 듣는 것입니다. 인간이 들을 수 있는 최소 압력단위인 20uPa 부터 그 위로 다양한 소리의 세기들이 결정됩니다.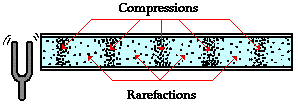
(http://www.physicsclassroom.com/Class/sound)
진동의 형태는 주파수와 밀접한 관련이 있습니다. 주로 중고등학교때부터 배워온 sin, cos 함수 등으로 진동이 표현된다고 볼 수 있겠습니다. 예를 들어 피아노의 경우, 특정 주파수를 가지는 '도'와 '미'를 연주했을 때, 우리는 두 음이 중첩된 소리를 들을 수 있습니다. 이는 각각의 음에 해당하는 sin 함수들이 더해진 파동의 형태가 귀에 전달된다고 볼 수 있습니다.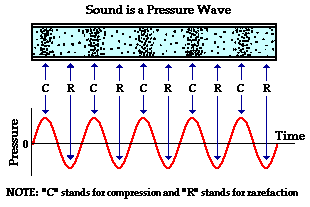
(http://www.physicsclassroom.com/Class/sound)
음성데이터란?
보통 우리는 컴퓨터에 음성데이터를 가지고 있습니다. wav파일이나 mp3 파일 등 익숙한 형태로 저장되어 있는데요. 이런 음성 데이터들이 어디서부터 오는지 생각해보면, 아마도 대체로 녹음실일겁니다. 실제 사람의 목소리나 악기들의 연주가 마이크를 통해 전기 신호로 변환되고, 이 전기 신호를 다시 컴퓨터에 저장하는 것입니다. 즉, 위에서 언급한 복잡한 sin 함수들의 합성함수가 컴퓨터에 그려지는 과정을 통해 데이터가 저장됩니다.
(https://www.mediacollege.com/audio/microphones/how-microphones-work.html)
아날로그에서 디지털로 변환되는 음성 신호
디지털로 변환된 데이터는 아날로그에 비해 한계가 있습니다. 컴퓨터는 특정 주기로 연산을 하기 때문에, 오리지날 신호 그 자체를 저장할 수 없기 때문인데요. 아래 그림을 보시면 이해가 될 것입니다. 부드러운 실제 우리가 듣는 아날로그 신호를 저장할 때, 컴퓨터는 특정 주기로 점을 찍는 방식으로 데이터를 저장하게 됩니다. 즉, 점 찍는 주기가 얼마나 빠르냐에 따라 아날로그 신호를 더 잘 저장할 수 있게 되는 것입니다. 이를 sampling rate이라고 하며, descrete signal processing에 자주 나오는 용어입니다. (사실 너무나 유명한 용어라..)
https://en.wikipedia.org/wiki/Sampling_(signal_processing)
nyquist frequency는 sampling rate의 반 값에 해당하는 주파수입니다.
nyquist frequency를 아는 것이 중요합니다. 예를 들어 아주 고주파(ex. 10kHz)까지 합성된 sin 합성 함수가 있다고 합시다. 이 때, 충분히 sampling rate을 작게, 즉 점을 더 많이 찍지 않으면 아주 고주파 영역은 디지털화하지 못하게 됩니다. 아래 그림을 보시면 됩니다. 아주~ 고주파의 경우, 점 찍는 주기보다 작아지기 때문에 그 점들로 표현할 수가 없게 되는 것입니다. nyquist frequeny는 sampling rate이 정해져 있을 때 어느정도까지 주파수 해상도가 나오는지를 결정하는 값이라고 볼 수 있겠습니다. 파이썬의 librosa 라이브러리를 통해 이 과정에 어떻게 표현되는지 추후 알아보겠습니다.

소리와 데이터 형태에 대해 간단히 알아봤습니다. 다음 포스팅에서는 파이썬을 이용해 음원 데이터를 불러오고 살펴보는 방법에 대해 알아보겠습니다.
'Developer > Librosa' 카테고리의 다른 글
| [Python 음성 데이터 분석] Librosa 라이브러리 사용법 (0) | 2020.07.28 |
|---|---|
| [Python 음성 데이터 분석] MFCC 개념 및 Librosa 사용방법 (0) | 2020.07.27 |
| [Python 음성데이터 분석] Librosa로 Mel Spectrogram 생성 (1) | 2020.07.24 |
| [Python 음성 데이터 분석] Librosa 라이브러리를 이용한 주파수 분석 (2) | 2020.07.23 |
댓글