지난 포스팅까지 Librosa 라이브러리의 short time fourier frequency에 대한 이론 및 방법에 대해 알아봤습니다. 이번에는 더 나아가, 음성데이터 분석에 주로 쓰이는 mel spectrogram에 대해 다뤄보겠습니다. 공부한 내용을 바탕으로 작성하기 때문에, 혹시나 잘못된 내용이 있으면 알려주시면 감사하겠습니다.
Mel-Spectrogram
인간의 귀는 컴퓨터와 달리, 주파수 간 간격이나 소리의 크기 등을 정확하게 판단하지 못합니다. 저주파대역인지, 고주파대역인지에 따라 판단하는 기준?이 달라지기 때문입니다. 예를 들어 사람이 500Hz와 1000Hz 소리는 쉽게 구분할 수 있습니다만, 10000Hz와 10500Hz는 구분하기 어렵습니다. 같은 500Hz 간격인데도 다르게 느껴지는 것입니다.
또한, 동일한 세기로 100Hz 소리를 들려줄 때와, 10000Hz 소리를 들려줄 때 사람이 느끼는 세기는 다릅니다. 같은 세기, 즉 같은 Pa 인데도 말입니다. 귀의 구조 때문에 발생하는 차이라고 하는데요.
mel-scale은 이러한 사람의 귀를 칼라맵인 스펙트로그램에 반영하는 것을 의미합니다. 보통 고주파로 갈수록 사람이 구분하는 주파수 간격이 넓어지는데요. mel scale은 이러한 원리를 이용해서 필터를 이용, 스케일 단위를 변환합니다.
 )
)
(https://en.wikipedia.org/wiki/Mel_scale)

(https://en.wikipedia.org/wiki/Mel_scale)
위 그림에서 보다시피, 주파수 대역별 mel 값으로 변환이 가능합니다. 즉, 지난 포스팅에서 stft가 linear한 Hz 해상도로 표현이 된다면, mel-scale은 관계가 공식과 같이 되는 것입니다. 칼라맵으로 mel 단위로 표현하면 stft와 차이가 발생하는 것을 볼 수 있습니다.
stft에 아래와 같은 mel-filter bank를 통과시키는 방식으로 만들 수 있습니다. )
)
(https://towardsdatascience.com/getting-to-know-the-mel-spectrogram-31bca3e2d9d0)
고주파로 갈수록 같은 mel 값을 가지는 주파수 범위가 넓어지는 것을 볼 수 있습니다.
Librosa를 이용해 스펙트로그램 생성
1 2 3 4 5 6 7 8 9 10 | n_fft = 2048 win_length = 2048 hop_length = 1024 n_mels = 128 D = np.abs(librosa.stft(y, n_fft=n_fft, win_length = win_length, hop_length=hop_length)) mel_spec = librosa.feature.melspectrogram(S=D, sr=sr, n_mels=n_mels, hop_length=hop_length, win_length=win_length) librosa.display.specshow(librosa.amplitude_to_db(mel_spec, ref=0.00002), sr=sr, hop_length = hop_length, y_axis='mel', x_axis='time', cmap = cm.jet) plt.colorbar(format='%2.0f dB') plt.show() | cs |
간단하게 mel spectrogram을 구현할 수 있습니다. 이 때, n_mels가 곧 칼라맵의 주파수 해상도가 됩니다. 즉, mel 기준으로 몇개의 값으로 표현할지를 나타내는 변수입니다. 많으면 많을수록 원래 stft로 표현한 칼라맵과 유사한 형태가 됩니다. 그만큼 필터를 촘촘하게 쓰는 것 같습니다.
Decibel Weighting (A, B, C... )
mel scale과 유사한 방식이 또 있습니다. decibel weighting입니다. 주파수에 따라 사람이 동일한 세기로 느껴지는 정도에 맞게 데시벨을 후보정해주는 것이라고 볼 수 있습니다. mel 방식은 주파수 해상도와 관련이 있었다면, decibel weighting은 해상도라기 보다는 주파수 세기와 관련이 있는 것 같습니다.
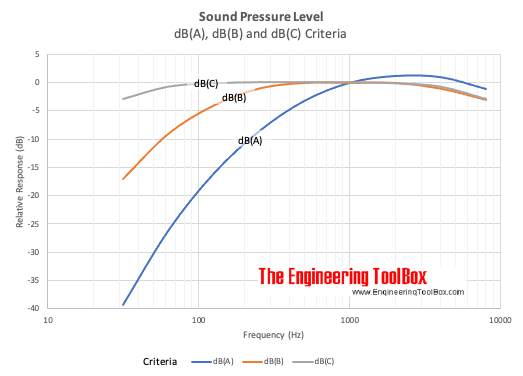
(https://www.engineeringtoolbox.com/decibel-d_59.html)
주파수에 따라 각 weighting별로 그래프 수치만큼 합산해줍니다. librosa에는 다음과 같은 함수를 제공합니다.
1 2 3 4 5 6 | freqs = librosa.cqt_frequencies(108, librosa.note_to_hz('C1')) aw = librosa.A_weighting(freqs) plt.plot(freqs, aw) plt.xlabel('Frequency (Hz)') plt.ylabel('Weighting (log10)') plt.title('A-Weighting of CQT frequencies') | cs |
B나 C 웨이팅은 기본 함수로는 제공하지 않는 것 같네요.
다음 포스팅에서는 Mel Frequency Cepstral Coefficient를 생성하는 방법 및 이론에 대해 알아보겠습니다.
'Developer > Librosa' 카테고리의 다른 글
| [Python 음성 데이터 분석] Librosa 라이브러리 사용법 (0) | 2020.07.28 |
|---|---|
| [Python 음성 데이터 분석] MFCC 개념 및 Librosa 사용방법 (0) | 2020.07.27 |
| [Python 음성 데이터 분석] Librosa 라이브러리를 이용한 주파수 분석 (2) | 2020.07.23 |
| [파이썬으로 음성데이터 분석하기] 소리와 데이터의 형태 (3) | 2020.07.22 |
댓글